class: center, middle, inverse, title-slide .title[ # Handle Missing Values ] --- class: inverse # New Functions - na_if - drop_na - fill - replace_na - package: vis_dat, VIM --- class: inverse, center, middle # Do we need to handle missing values? --- class: inverse, center, middle # No if just doing some calculations on the data --- class: inverse ```r library(tidyverse) df <- read_csv('https://bryantstats.github.io/math421/data/titanic_missing.csv') df %>% summarise(mean_age=mean(Age, na.rm=TRUE)) ``` ``` ## # A tibble: 1 × 1 ## mean_age ## <dbl> ## 1 29.7 ``` --- class: inverse, center, middle # No if just doing Visualization --- class: inverse ```r df %>% ggplot(aes(x=Age, color=Sex))+ geom_density() ``` 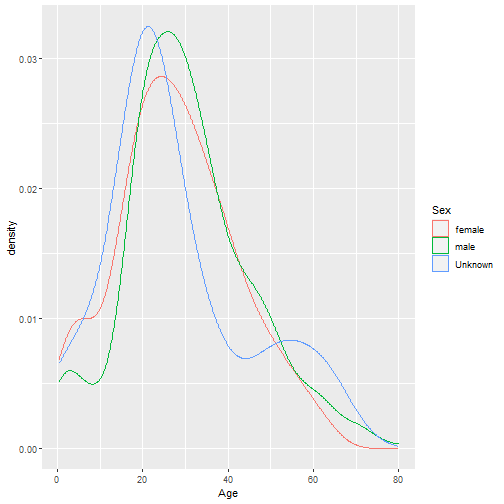<!-- --> --- class: inverse # When do we need to handle missing values - When you know the values of the missing values - When building predictive models - Other cases? --- class: inverse, middle, center # Checking the NAs --- class: inverse ```r # Missing values by columns colSums(is.na(df)) ``` ``` ## Survived Pclass Sex Age SibSp Parch Fare Cabin ## 0 0 0 177 0 0 0 687 ## Embarked ## 2 ``` --- class: inverse ```r # Missing values by columns colMeans(is.na(df)) ``` ``` ## Survived Pclass Sex Age SibSp Parch ## 0.000000000 0.000000000 0.000000000 0.198653199 0.000000000 0.000000000 ## Fare Cabin Embarked ## 0.000000000 0.771043771 0.002244669 ``` --- class: inverse # Steps to Handle missing values - Step 1: Identify all the forms of Missing Values ('Unknown', 'Missing','9999'...) - Step 2: Convert them to `NA` - Step 3: Handle it - Approach 1: Remove rows that have any NAs - Approach 2: Fill NAs with the previous or next value of the column - Approach 3: Replace by the mean, majority or a predicted value. --- class: inverse # Step 1: Identify forms of missing ```r colSums(df=='Missing', na.rm = TRUE) ``` ``` ## Survived Pclass Sex Age SibSp Parch Fare Cabin ## 0 0 0 0 0 0 27 0 ## Embarked ## 0 ``` --- class: inverse # Step 2: Convert all missing to NA ```r # Convert Unknown, Missing and Not Available to NA df <- replace(df, df == 'Unknown' | df == 'Missing' | df == 'Not Available', NA) ``` --- class: inverse # Approach 1: Drop rows - Drop rows that have any NAs ```r drop_na(df) ``` ``` ## # A tibble: 167 × 9 ## Survived Pclass Sex Age SibSp Parch Fare Cabin Embarked ## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <chr> <chr> <chr> ## 1 1 1 female 38 1 0 71.2833 C85 C ## 2 1 1 female 35 1 0 53.1 C123 S ## 3 0 1 male 54 0 0 51.8625 E46 S ## 4 1 3 female 4 1 1 16.7 G6 S ## 5 1 1 female 58 0 0 26.55 C103 S ## 6 1 2 male 34 0 0 13 D56 S ## 7 1 1 male 28 0 0 35.5 A6 S ## 8 0 1 male 19 3 2 263 C23 C25 C27 S ## 9 1 2 female 29 0 0 10.5 F33 S ## 10 0 3 male 25 0 0 7.65 F G73 S ## # ℹ 157 more rows ``` --- class: inverse - Drop rows that have any NAs in Age or Sex ```r drop_na(df, Age, Sex) ``` ``` ## # A tibble: 689 × 9 ## Survived Pclass Sex Age SibSp Parch Fare Cabin Embarked ## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <chr> <chr> <chr> ## 1 0 3 male 22 1 0 7.25 <NA> S ## 2 1 1 female 38 1 0 71.2833 C85 C ## 3 1 3 female 26 0 0 7.925 <NA> S ## 4 1 1 female 35 1 0 53.1 C123 S ## 5 0 3 male 35 0 0 8.05 <NA> S ## 6 0 1 male 54 0 0 51.8625 E46 S ## 7 0 3 male 2 3 1 21.075 <NA> S ## 8 1 3 female 27 0 2 11.1333 <NA> S ## 9 1 2 female 14 1 0 30.0708 <NA> C ## 10 1 3 female 4 1 1 16.7 G6 S ## # ℹ 679 more rows ``` --- class: inverse # Drop columns with missing values ```r df %>% select(-Age, -Sex) ``` ``` ## # A tibble: 891 × 7 ## Survived Pclass SibSp Parch Fare Cabin Embarked ## <dbl> <chr> <dbl> <dbl> <chr> <chr> <chr> ## 1 0 3 1 0 7.25 <NA> S ## 2 1 1 1 0 71.2833 C85 C ## 3 1 3 0 0 7.925 <NA> S ## 4 1 1 1 0 53.1 C123 S ## 5 0 3 0 0 8.05 <NA> S ## 6 0 3 0 0 8.4583 <NA> Q ## 7 0 1 0 0 51.8625 E46 S ## 8 0 3 3 1 21.075 <NA> S ## 9 1 3 0 2 11.1333 <NA> S ## 10 1 2 1 0 30.0708 <NA> C ## # ℹ 881 more rows ``` --- class: inverse # Approach 2: Fill in missing values with previous or next value ```r df %>% fill(Age, Sex, Cabin, .direction = 'updown') ``` ``` ## # A tibble: 891 × 9 ## Survived Pclass Sex Age SibSp Parch Fare Cabin Embarked ## <dbl> <chr> <chr> <dbl> <dbl> <dbl> <chr> <chr> <chr> ## 1 0 3 male 22 1 0 7.25 C85 S ## 2 1 1 female 38 1 0 71.2833 C85 C ## 3 1 3 female 26 0 0 7.925 C123 S ## 4 1 1 female 35 1 0 53.1 C123 S ## 5 0 3 male 35 0 0 8.05 E46 S ## 6 0 3 male 54 0 0 8.4583 E46 Q ## 7 0 1 male 54 0 0 51.8625 E46 S ## 8 0 3 male 2 3 1 21.075 G6 S ## 9 1 3 female 27 0 2 11.1333 G6 S ## 10 1 2 female 14 1 0 30.0708 G6 C ## # ℹ 881 more rows ``` --- class: inverse # Approach 3: Replace Missing values with replace_na ```r # Replace by the mean (numeric variable) mean_age <- mean(df$Age, na.rm=TRUE) df$Age <- replace_na(df$Age, mean_age) ``` --- class: inverse # Replace Missing values with replace_na ```r # Replace by the majority (categorical variable) majority_sex <- names(which.max(table(df$Sex))) df$Sex <- replace_na(df$Sex, majority_sex) ``` --- class: inverse # Replace Missing values with replace_na ```r # Replace by the majority (categorical variable) majority_class <- names(which.max(table(df$Pclass))) df$Pclass <- replace_na(df$Pclass, majority_class) ``` --- class: inverse, middle, center # Package VIM --- ```r library(VIM) df <- read_csv('https://bryantstats.github.io/math421/data/titanic_missing.csv') df <- replace(df, df == 'Unknown' | df == 'Missing' | df == 'Not Available', NA) ``` --- ```r aggr(df) ``` 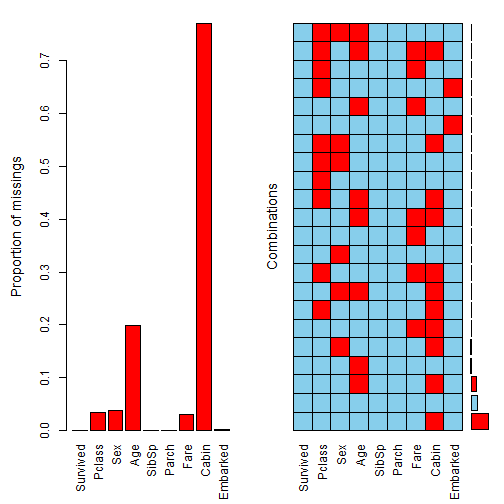<!-- --> --- class: inverse, middle, center # Package vis_dat --- ```r library(visdat) df <- read_csv('https://bryantstats.github.io/math421/data/titanic_missing.csv') vis_miss(df) ``` 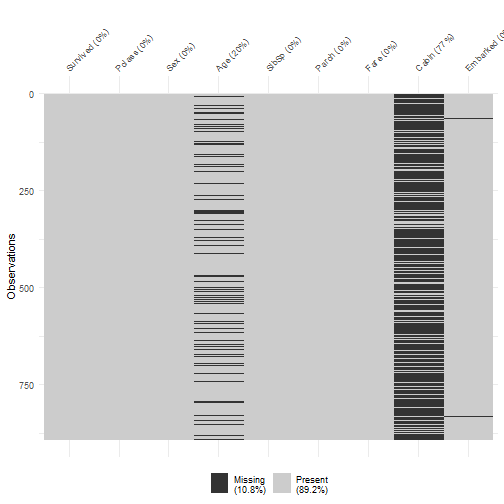<!-- --> --- ```r vis_dat(df) ``` 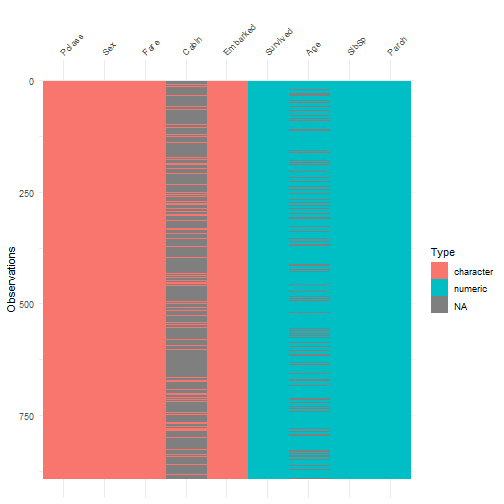<!-- --> --- ```r vis_expect(df, ~.x == 'Missing') ``` 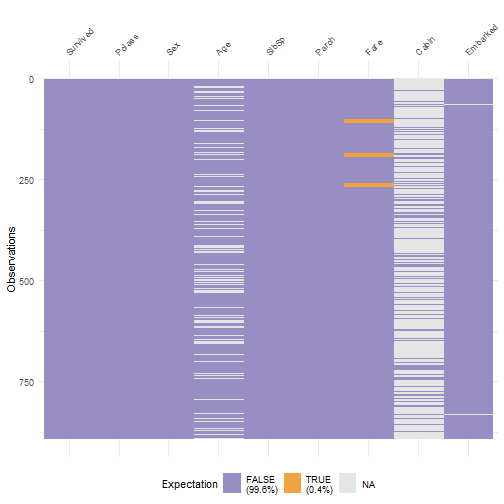<!-- --> --- ```r vis_expect(df, function(x){x == 'Missing'|x=='Unknown'| x=='Not Available'|is.na(x)}) ``` 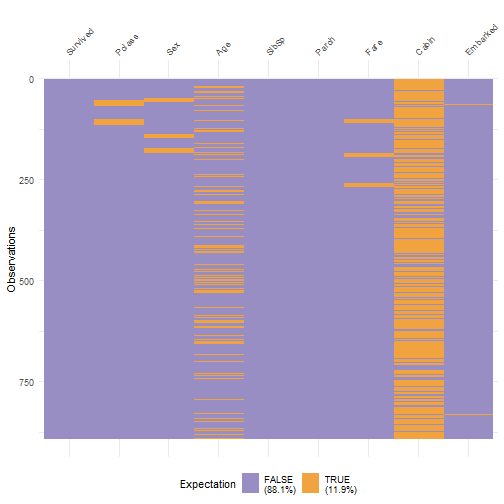<!-- -->